This article will give an overview of the basic and fundamental notions of ML. It is part of a series developed for practitioners. The goal is to be rapidly able to apply and make use of ML.
There is a general introduction to Machine Learning on Wikipedia. We have no intention of cloning the content of that article here, unlike many people trying to explain what ML is.
Everybody can understand what is Machine Learning because the definition is contained in the name, these are machines that “learn”, e.g machines which are able to consume data in order to improve their tasks given feedback from the environment where they do perform these tasks
 As humans we usually learn a lot - at least we should. We learn from our childhood the alphabet, how to write and read, usually painfully. We learn calculus, computations and how to distinguish the various objects that will populate our everyday’s life.
As humans we usually learn a lot - at least we should. We learn from our childhood the alphabet, how to write and read, usually painfully. We learn calculus, computations and how to distinguish the various objects that will populate our everyday’s life.
The mechanisms of learning - at least in our childhood- are fundamentals. We know example of wild childs like ‘wolf children’ or ‘dog children’’ or other cases of children raised by primates. In these cases, the humans did not learn properly and were at least partly “trained” by non-humans (animals). The result was a deficiency in human intelligence and an inability to resolve basic problems that any other “properly trained” humans could address.
In our lives, we usually learn from mistakes and errors. Things that hurt us or fool us and we are able to solve such errors, mainly by learning and adapting to the new situation.
The basis of Machine Learning comes from a 1950 paper authored by Alan Turing and named "Computing Machinery and Intelligence". In that paper, Turing offers to replace the question “Can Machine think?” by other questions such as “Can machines do our work?” , “Can Machine win a game ?”, and among others “Can machine learn ?”.

In fact, Turing mentioned the Learning Machines and not the Machine Learning which is anyway the “ancestor” concept.
A Machine that could learn would be a “child” machine and would experience ,same as the humans, heredity, mutation, experiments and choices following the experiments. Complexity would be at stake so that despite strong “formal” and “imperative” logic, a self-built model with a proper logic would be built as a result of the learning. This presupposes ignorance of the child machine and also some strong randomness.
Machine Learning is therefore defined as an algorithm which is somewhat mimicking the Human learning process.
The Human learning process is complicated. It involves heredity, mutations, evolutions, probability, randomness, neurons, memory and other factors. The Machine Learning algorithms often use partially the aforementioned factors.
General Principles of ML
The “primitive” idea behind ML is a machine which is fed by data, a “training set” and which builds a model, usually a decision, choice and strategy model, using these data in order to perform some tasks in an environment, independently of any human intervention, depending on the response of the environment, a feedback can be generated, which can take various shapes : “right” or “wrong” or a decimal score of a feature vector for instance. That feedback, coupled to the data from the environment can be integrated into the previous dataset to create a new dataset from which a new model can be built and so on.
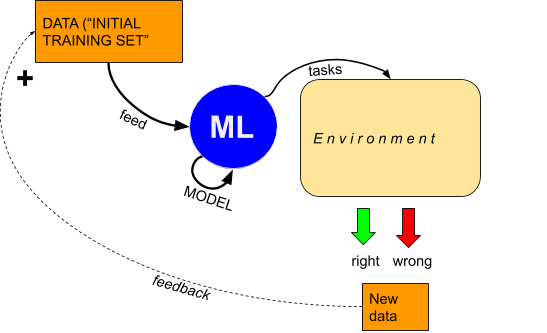
This presuppose the following components:
- The data (“learning set”);
- A model builder (the ML in itself);
- Task(s) to perform in an environment;
- The environment;
- Feedback from the tasks.
Learning machines and Machine Learning
At this stage, the reader understands that a learning machine is a Machine Learning with data, tasks and interaction with an environment. As itself, machine learning is doing nothing and unable to evolve if nothing is “injected” inside.
A learning machine is, therefore, a dynamical self-evolving system and the way it interacts and learns from its errors and from the environment is as much as fundamental as the algorithm/model it implements.
Machine Learning and Dynamical systems
As the ML will learn and be trained and as we iterate the training steps, the model will go through the space of all the possible models
When the learning algorithm converges, this is similar to a dynamical system reaching an equilibrium state.
The “Learning” phase of a learning machine can be seen as a time system, especially if loops are introduced. This is especially true for Recurrent Neural Networks (RNNs).
In the original concept by Turing, the learning phase of a machine is similar to the education of a child and therefore induces time, contingents, possibilities etc… which makes it relevant to be interpreted as a dynamical system.
In such an approach, concepts as Markov chains, Lyapunov stability are very relevant to ML in general.
Supervised, unsupervised and Reinforcement Learning
The learning process of ML falls into two three different categories: supervised and unsupervised learning, or reinforcement learning.
Supervised learning can be seen as the machine being educated through a human “supervisor” which guide in some ways the learning while unsupervised learning can be seen as “wild” learning - more like raw self-organization and convergence to an equilibrium.
The difference may also be seen between the human process of learning, where learning consists mainly of education with teachers (“supervisors”) while animals learn more from their environment in general and self-adapt to that environment without supervision and this relates more to unsupervised learning.
What is known as “street smart” also refers largely to some unsupervised learning, e.g. the ability to learn without guidance and supervision into an unknown environment.
Unsupervised learning can be seen as well as Human research, facing unknown situations and learning from these unknown situations, eventually self-creating labelled categories.
A mixture of supervised and unsupervised learning is always possible. This situation is named semi-supervised learning.
In general, supervised learning in ML will use labelled data. These are data - which can be of any sort - provided with a label (either by humans either from other machines) . This label indicates the nature of the data and how they must be interpreted by the machine. The task of ML will therefore be to consume a new unlabeled set of data and guess, predict and label them (eventually creating new labels) or classify them (fixed finite amount of labels).
A third category (the three basic ML paradigms[1]) is reinforcement learning. In that approach the teaching is conditioned by ‘rewards’ or ‘penalties’. The analogy with human learning is obviously the punishment from parents, the fines and various punishments from the law enforcement systems or the gifts, ‘bonus’, various perks and medals provided by the educational, military or civilian bodies.
Reinforcement learning is especially relevant to game theory.
Multi-agents ML
A set of Ml units may be coordinated and cooperative. In that case we speak of Multi-agents ML. For instance a group of 1 million of ANNs which are single agents ML may be connected together - as black boxes - and cooperate together with further algorithms. This can be seen as a “team” for instance.
Some entry points for understanding ML
Here we list some of the most common ML algorithms and terminologies, and we explain briefly what they do. The literature on the subject is obviously infinitely vast, and we only aim here at giving a few entry points.
|
Algorithm name |
Description |
|
ANN- Artificial Neural Network |
ANNs are based on a simulation of the known behavior of the human brains, using synapses and neurons. This is an imperfect simulation which does not fully represent the real functioning of Human neurons and uses an artificial mechanism known as backpropagation which does not exist in biological systems. In ANNs, nodes (aka 'neurons’) receive signals from other neurons and transform that signal and communicate it to other nodes. ANNs use weight functions to transform the signal. There are different types of ANNS:
|
|
Perceptron |
The perceptron is a linear algorithm used for input classification and decides to which class a data belongs to. |
|
Deep Learning |
Deep learning is generally a class of ANNs which is using a very important number of layers (hence the term “deep”) , which layers are aggregates of neurons.Simplest type of Deep learning networks are the feed forward neural networks. |
|
Hopfield networks |
A form of recurrent ANN |
|
Boltzmann Machines |
A stochastic Hopfield network where nodes are divided into “visible” and “hidden” nodes. Boltzmann machines make use of Markov processes (hence they are “stochastics”) and are designed to be used to solve combinatorics problems. A Boltzmann machine is said to be restricted if there are no intra-layers communications. |
|
CNN-Convolutional Neural Networks |
These are fully connected ANNs, e.g. where all neurons are connected with each other in the layers. If there are a lot of layers, we say this is a “deep” CNN. An example of Convolutional network is LeNet-1. |
|
Recursive neural networks |
A deep hierarchical ANN where all weights are the same |
|
Recurrent Neural networks |
An ANN where the neurons form a directed graph so that it induces a time series |
|
Bayesian Classifiers |
The most important type of ML classifiers, using supervised learning and Bayesian probabilities and Bayesian statistics. |
|
Bayesian network |
Bayesian classifiers which are not “naive”, e.g. where the conditional probabilities are not independent. |
|
Hidden Markov Model Classifiers |
A special type of Bayesian Network used to model dynamical systems. Used for automatic recognition of handwriting, speech, etc… |
|
Deep Belief Learning |
A stack of restricted Boltzmann machines designed such that all layers communicate with each other, namely the predecessor with its successor. |
|
Regressors |
Regressors are used to predict continuous data (by statistical regression analysis) while classifiers work on a finite set of outputs which are streamed into categories. |
|
Evolution learning |
Evolution learning is a class of ML meta-heuristic algorithms which often uses collective computational systems as found in nature, implying fitness and evolution mechanisms. Here is a list of evolutionary algorithms:
Additionally, ML algorithms can themselves evolve through a “Darwinism” process. |
|
Binary Tree search |
Tree search algorithms can be used with Monte-carlo methods to perform Monte-carlo tree searches (MCTS). Binary tree search is used in a wide range of Machine learning algorithms. See also: Decision Tree Classifiers Random Forest Classifiers |
|
Support Vector Machines |
SVMs are classifiers which construct hyperplanes in a multidimensional space, which separate two categories of data. It’s the best representative of Kernel methods-based MLs. See also: KNN Classifiers |
|
(DRL) Deep Reinforcement Learnings |
DRL is just the combination of deep learning and reinforcement learning. |
|
Q-Learning |
A reinforcement learning algorithm. |
|
Fusion Classifiers |
Meta-classifiers that combine several different types of classifiers to combine the “best of two world” and maximize the overall classification accuracy. See also: AdaBoost classifiers |
Conclusion
In that brief introduction to ML, we tried to be as complete as possible. Of course - as of 2020 - ML is actually a very important and strategic field of research and the concepts and notions change all the time. Nevertheless we described in that article an overview of the basic and fundamental notions of ML.

[1] There are many more alternative definitions of ML paradigms...