In an organization’s cyber security environment, problems change from week to week. Consequently, a constant strive to learn within the team is of utmost importance as new and exciting challenges need to be faced each week. Within this ever-evolving environment, it’s critical that a team should constantly be changing, evolving and learning in order to adopt the practice of continuous improvement towards improving the company’s security posture (Kaizen).
In this article, we discuss a recommended program that empowers every team member and creates unity across all tools within the CSIRT ecosystem. We also take into consideration the ‘information overload’ and ‘noise’ of false positives - false positives are the new normal - never be afraid of them - here we provide direction around a better way to distinguish between false positives and real potential incidents.
Look out for the weird, suspicious or out of the ordinary!
Jim Byrge
Just about anything, from identifying suspicious user activity to discovering malware, could be defined as a cyber event. So, how can you know when it’s time to put a comprehensive incident response strategy in place?
Iterative process of Detection, Response, Analysis, Validation and Improvement
The following infographic shows an iterative process on how to set up indicators for detection, detecting and responding to incidents, learning from these incidents and documenting, potentially performing manual tests and analysis, and test chosen indicators across historical data, followed by subsequent improvement.
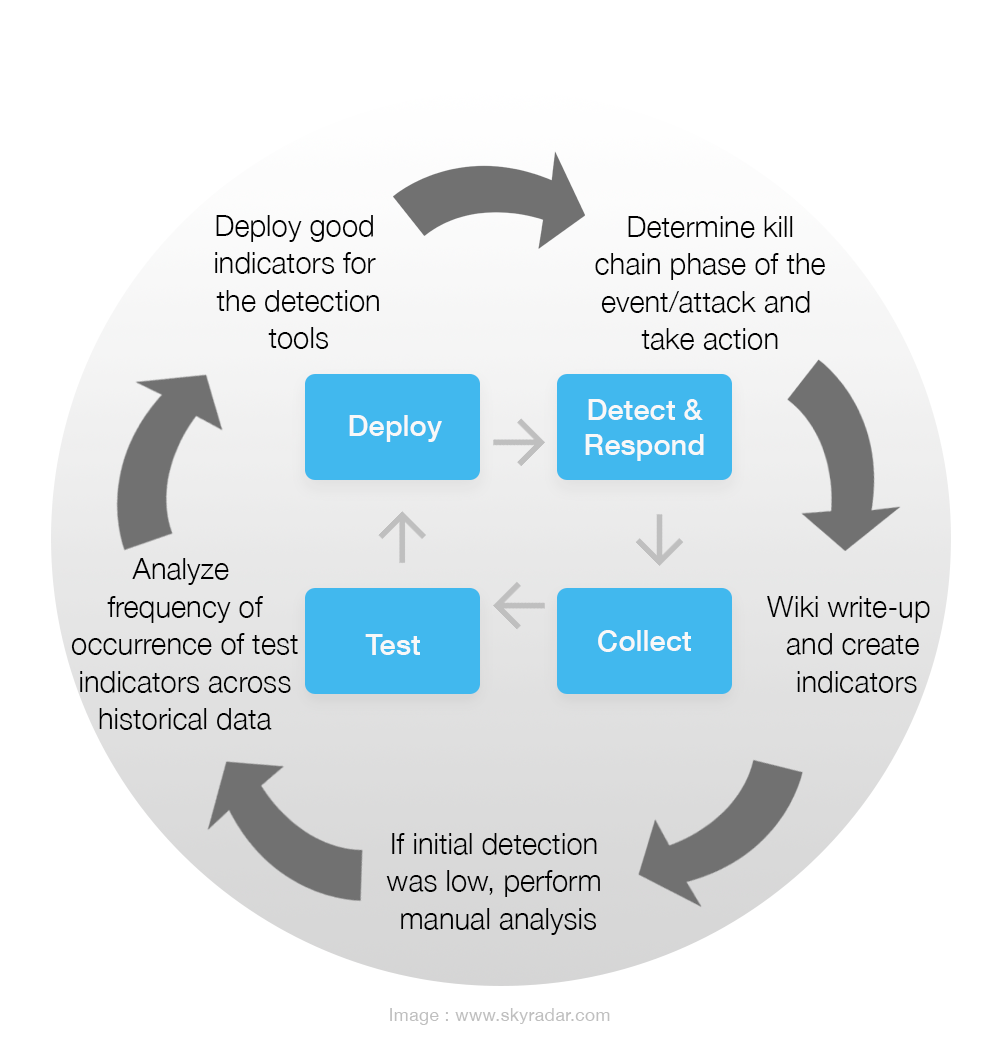
Let us now walk through such a process:
- An alert is received and consideration is applied as to how far in the kill chain the attack actually went and this is then examined. Create an event. Start taking notes
- Write-up a Wiki & create indicators
- indicators of compromise - forensic data- evidence of of potential intrusions
- indicators of maliciousness - may not be 100% like a compromise, however it provides indicators that something is suspicious and requires investigation - Take these indicators and write up notes following investigation and work out what requires to be tested
- Carry-out detection - if detection is low, look further and deeper to see if something has been missed - perform manual analysis, if necessary - test
- Look at the frequency of analysis in order to test indicators across historical data - look across history and see how many times these potential attacks/ alerts have hit
- Decide whether or not you wish to deploy these alerts as good indicators to production for your detection tools. For example; a SOAR takes the hunts that have been created and runs them through an internal process in order to establish how many times the activity has actually entered the environment;
- low alerts - create a hunt to look for this in the future.
- high alerts - why? Is this a normal process that is being seen in an environment - Ask the question- what does normal look like? And escalate, if necessary
What does normal look like?
Does your linux team recover the ROOT password then install new software? Ask questions…
“I noticed a few days before that more and more traffic around the reckoning of the box… I thought it meant something. I found it before the patch was out” Jim Byrge
- What is weird or suspicious? Focus on the indicators that have got through your enterprise tools (gateways, firewalls, anti-virus etc) that probably tackle or block around 90% of malicious activity. Find ways to detect on the alerts that have managed to get through
- Work backwards from compromised in order to identify a compromise! Here’s an example;
Credentials stolen from a user in a company that uses 2FA;
- Phishing email(s) arrives
- User clicks on the link in the phish
- User goes to the website (the credentials harbouring site), enters their password
- Adversary then has credentials and begins to use them & attempts to log-in
Observation - the organization notices a 2 factor push at the time of the phish - Organisation has alerts based on emails that come in - locate emails
Result - Locate user that has been compromised, password is then reset
Ongoing Improvement Towards Effective Incident Response
In the beginning, there will be many false positives, and this is to be expected- it’s a very common issue. An indicator that was relevant and accurate 5 years ago might not mark malicious behavior today. Then, moving forwards, begin to filter out the activities which are legitimate, and start identifying others which are malicious.
Cast a wide net when looking for things - false positives are normal
Jim Byrge
Looking at external intel is equally as important. In this way, an internal intel process can be built upon- understanding the problem and putting defensive strategies in place. Subjects, URLs, techniques. Keep building intel. Don’t be afraid of false positives- just make sure you understand what’s ‘weird’!
With prioritization and learning to reduce false positives, this can reduce the barriers to effective incident response, allowing the team to focus on areas of real importance.
In our next article, we take a look at an expert’s suggested workflow and take a deeper dive into how threats and risks are identified.
This article is founded on the webinar “Building your Cybersecurity Program”, by Jim Byrge.

References
- “Building your Cybersecurity Program” (2021), by Jim Byrge in cooperation with VMRAY.com