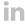As part of our series on how incident response teams leverage different parts of the security stack for investigations, we now are going to look at how anti-virus logs are used and can be used.
For background, anti-virus logs can be leveraged for many investigation types including, but not limited to, insider threats, ransomware, trojan infections, data loss from malware infections, root kits among many other related security threats. Unlike previous articles that focused on a specific use case for the component of the security stack, the following will highlight common use cases for reviewing anti-virus logs and how to leverage them for each investigation.
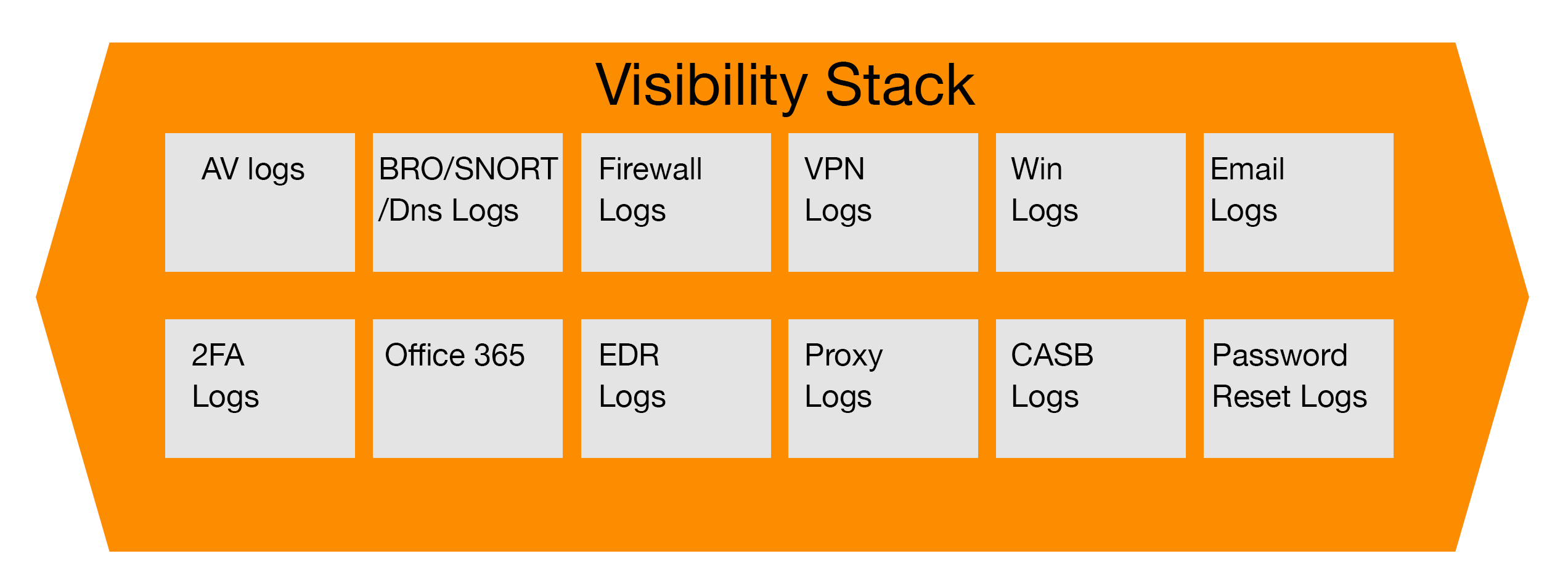
Insider Threats
Many people may argue that anti-virus logs aren’t the primary point of information for investigating insider threats. However, depending on the end point solution in the environment, and how it is configured, useful information can be gleaned from these logs. Security teams normally have the anti-virus logs sent to a security information event manager or SIEM. Activity that usually creates alerts include USB usage on end points and servers, changes in security configurations, the disabling of anti-virus on end points and evidence of abnormal data access. With this data, incident response teams can follow the documented process for addressing this threat, whether it is informing the employee’s manager or human resources.
Fig 1. Sample screen shot from Crowdstrike console
Ransomware
Ransomware is an extremely dangerous and fast-moving threat on any organization’s networks. It can result in significant data loss and the loss of access to computer systems within the bank or other financial institution, If left undetected or detected too late. Threat actors will then take advantage of the opportunity to steal data from their target and hold it hostage until a ransom is paid, which is typically in the millions of dollars via bitcoin.
Anti-virus or endpoint protection logs will and do play a major role for the incident response team in evaluating what transpired on the network and try to determine the initial event that triggered the ransomware to be downloaded and executed. In most cases, the team will need to review the logs on numerous end points before determining what is known as “patient zero.” The time to identify the initial infected machine is greatly reduced as organizations replace their traditional end point solutions with next generation solutions that help identify, triage and mitigate ransomware infection attempts.
The following is what is found when using an endpoint solution known as Sentinel One. The reader should notice that this diagram shows the chain of events that occurred once the ransomware was executed on the end point. As a result of identifying the original source of the ransomware attack, the team may potentially be able to obtain a sample of the malware and other indicators of compromise and utilize this data to strengthen their future security posture to mitigate it from happening again.
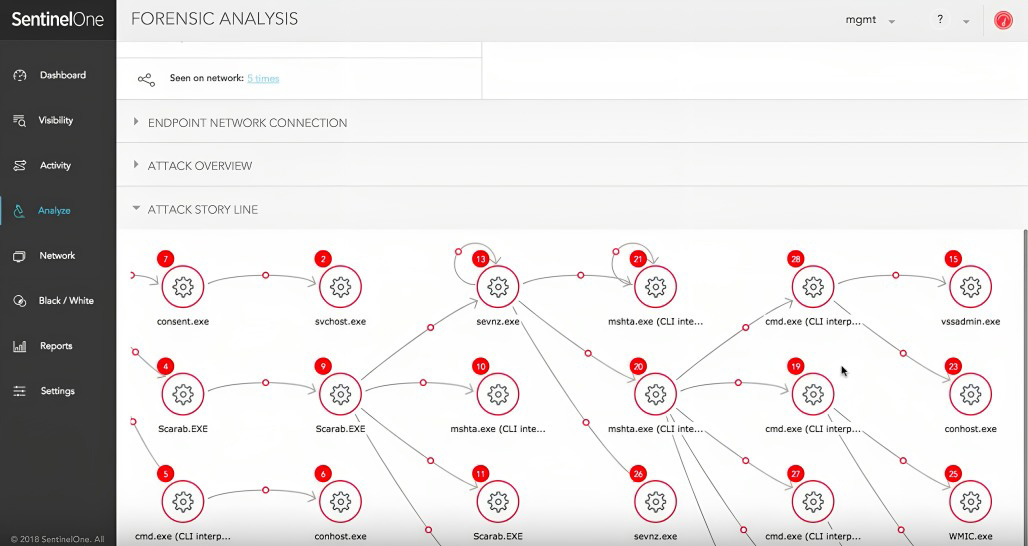 Fig 2 SentinelOne console analysis console showing analyst tab for chain of events (Photo Credit: https://www.sentinelone.com/blog/ransomware-ransom-based-malware-demystified/)
Fig 2 SentinelOne console analysis console showing analyst tab for chain of events (Photo Credit: https://www.sentinelone.com/blog/ransomware-ransom-based-malware-demystified/)
Lateral Movement Detection
Once a threat actor gains access to a target network, the next course of action typically involves either using the netstat command to show the network configuration for the device, ARP Cache, Ipconfig, local routing or PowerShell. After the reconnaissance step is complete, the next stage you want to try and look for post compromise are signs of credential dumping and/or privilege escalation, that will allow them to move to other devices on the company network.
Typical methods most modern solutions should detect that you should look for include pass the hash, pass the ticket, signs of key logging tools or even hacking tools like Mimikatz which many state sponsored threat actors like to use to capture all credentials from an environment. Often, the best approach to catch a lot of this activity is to have a dedicated team that hunts for threats based on this behavior. However, many times solutions can be configured to automatically detect and prevent lateral movement using the above-mentioned techniques.
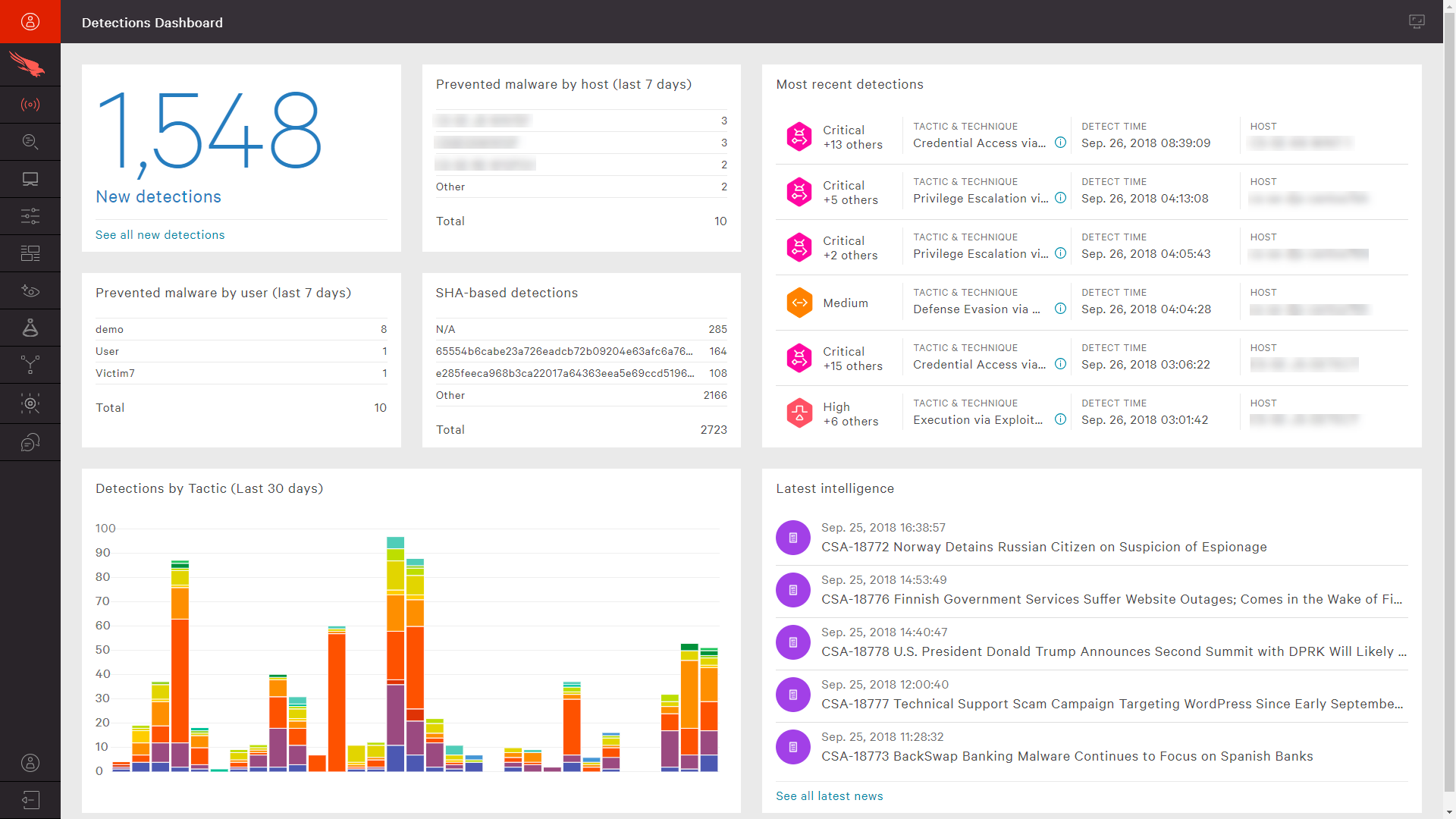
Fig 3. Dashboard in Crowdstrike which alerts teams to lateral movement (Photo Credit: https://www.crowdstrike.com/cybersecurity-101/lateral-movement/)
Summary
Historically, certain industries such as financial institutions could not easily detect the above-mentioned threats with traditional tools. However, as more advanced solutions, such as Crowdstrike or their competitors, replace outdated technology, incident response teams will be in a much better position to create play books that automatically detect, respond and remediate threats whether it is ransomware attacks, insider threats attempting to to steal company data using USBs, or threat actors that try to use lateral movement to go undetected. This has resulted in reduced times to detect and remediate, saving the organization money and time in the long run by preventing the company from having to recover from incidents that traditionally were not blocked.

References
- “Building your Cybersecurity Program” (2021), by Jim Byrge in cooperation with VMRAY.com